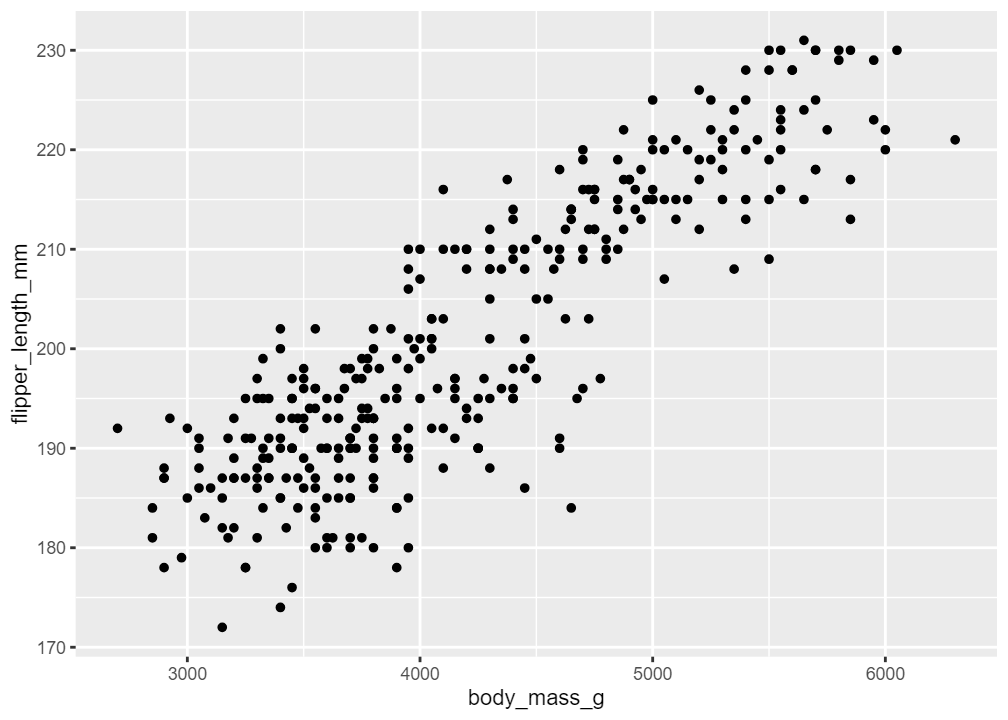
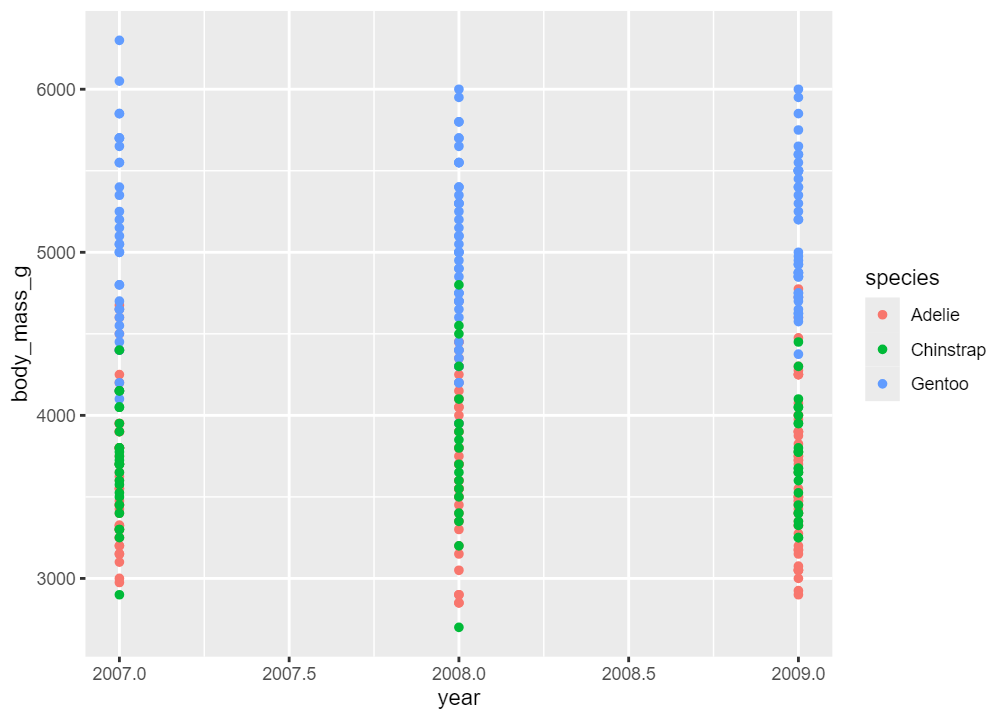
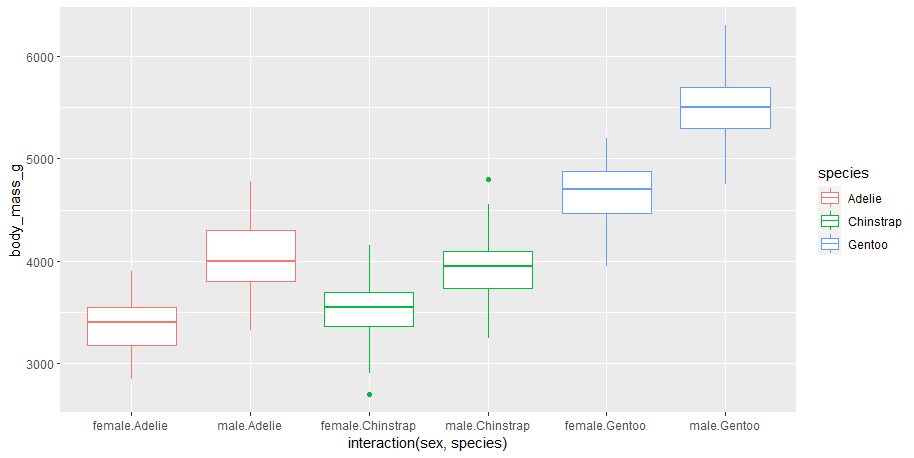
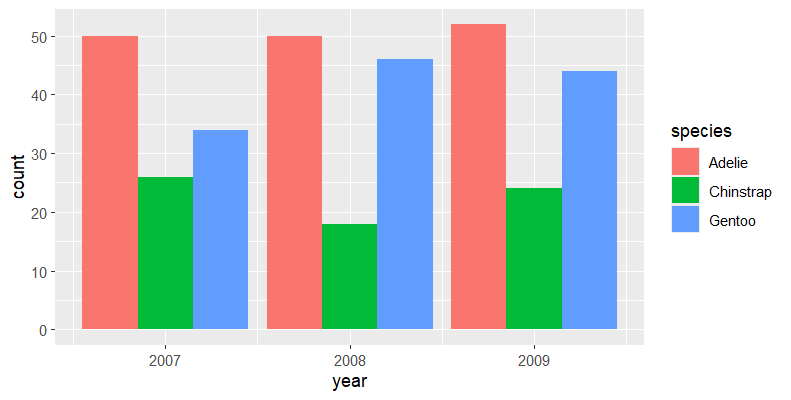
The Gentoo species has had the highest average body mass over the three years. Chinstrap increased in 2007 and dropped in 2009 while Adelie seems to have peaked in 2009
Been trying to practice with own data in Rstudio but I am failing to access the tidyverse packages so I can sun ggplot.
Is your tidyverse problem caused by the amount of time it takes to download and install the tidyverse? It has so many packages! Have you tried installing only those packages you need, e.g. ggplot2, readr, dplyr?
Or is it another error, that we can maybe help with?
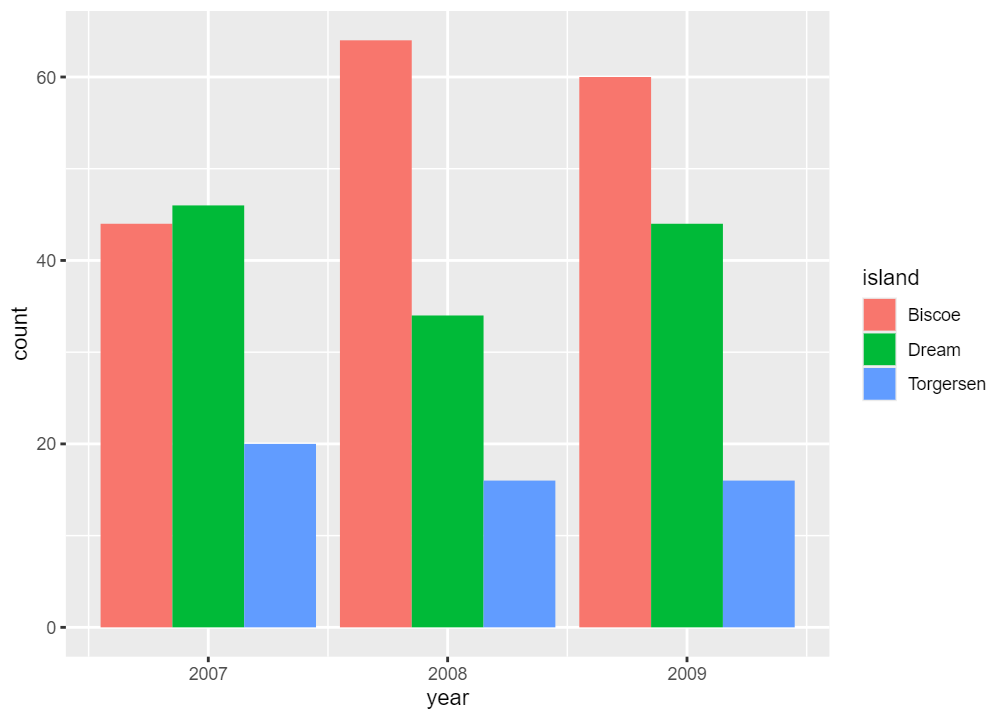
3.The largest sample size is on Biscoe island , followed by Dream then Torgen with the least ; across all years .
I have been having trouble running these codes on my own data in R studio .I keep getting an error or “NULL” when I edit and run these codes . I downloaded functions, so will try to find out where exactly I am missing it . Kinda frustrating to be getting all these errors , however, its part of the learning I suppose. A few hiccups before getting it right !
Coding can be really frustrating, but on the flip side, when it goes smoothly it is very satisfying! We just need to get you to that point…
This week’s learning activities include importing data, assigning the appropriate data type, and correcting errors, so perhaps you’ll find some answers to your problems there, later today
Do share the error messages you’re getting, either as a screenshot or copy/paste your code and the error, with a brief description of your data and/or what you want the code to do
Now that others have posted their assignments, you can have a go at the final Feedback step and complete your assignments @Alice_Laguardia, @Nicorll, @Kundai and all
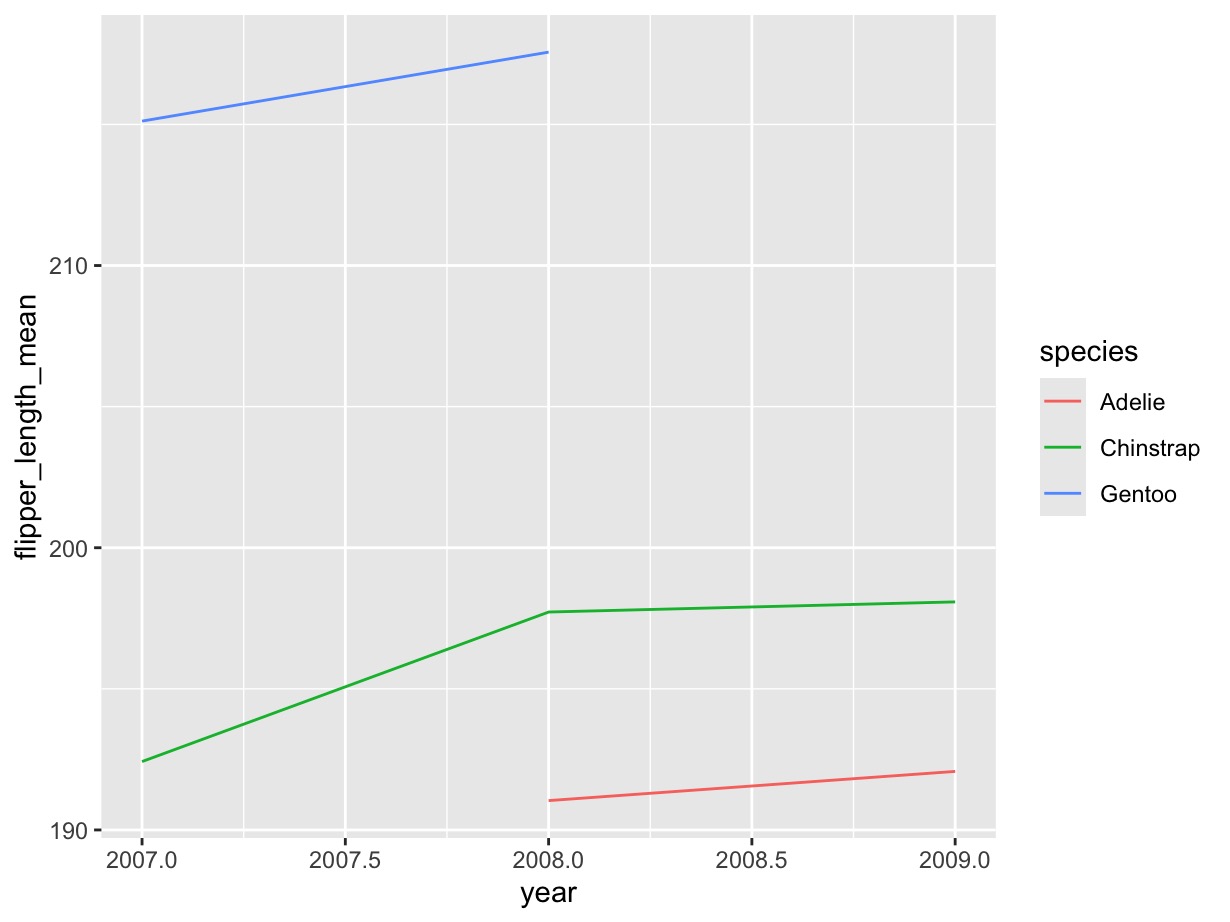
Interpretation: Mean flipper length slightly increased over time, for all three species, and thus overall. This could indicate that penguin sizes are potentially becoming larger.
Brief reflection: My next step will be to try out these plotting methods on my own data. I’ll hopefully be able to post some results here!
Feedback: @Nicorll Great line scatterplot! I find them harder to interpret than other plotting techniques. What type of plot do you think would be best suited to easily visualise this data?
And a suggestion/idea for all of us as we advance our plot-making skills, to ensure they are as reader-friendly as possible — to explore which colour schemes are best to address colourblindness!
2. Code
"library(tidyverse) # loaded to remove missing data
penguins_weight ← penguins %>% # create new dataset to exclude all N/A for certain variable
drop_na(body_mass_g) %>% # remove all n/a
drop_na(sex) %>% # remove all n/a
drop_na(species) # remove all n/a
head(penguins_weight) # check data + opened data frame
ggplot(penguins_weight, # used modified dataset
aes(x = interaction(sex, species),
y = body_mass_g,
colour = species)) +
geom_boxplot() "
Intrepretation: males are heavier than females for each of three species. The Gentoo species ( both males and males) both have higher median weights compared to the other two species. Whereas the gender weights of Adeile and Chinstrap species are similar
Reflection: Good summary of different plot types and uses and how to quickly cross check dataset using names.(). Visualisation of the plot is easy to interpret. It would be nice in this stage to modify x labels aswell as both axis titles
(btw. if I surround the code with ```, the code is not complete once published)
Adelie penguins were the most represented in the measurement each year. Followed by Gentoo and then Chinstrap penguins.
I wanted to put year and island on x line to know specificaly how many individuals were measured each year on every island. I tried some combinations, but nothing worked out
I don’t have a feedback rather than question. In code:
“penguins_summary ← penguins %>%
group_by(sex, year) %>%”
what does %>% do? Or what does it stand for?
Hello,
I tried to use my own dataset but I will have to wait to complete the next module to know how to prepare the data to be imported in R.
Being extremely stubborn I insisted and create a couple of plots with the leaf data we collected together.
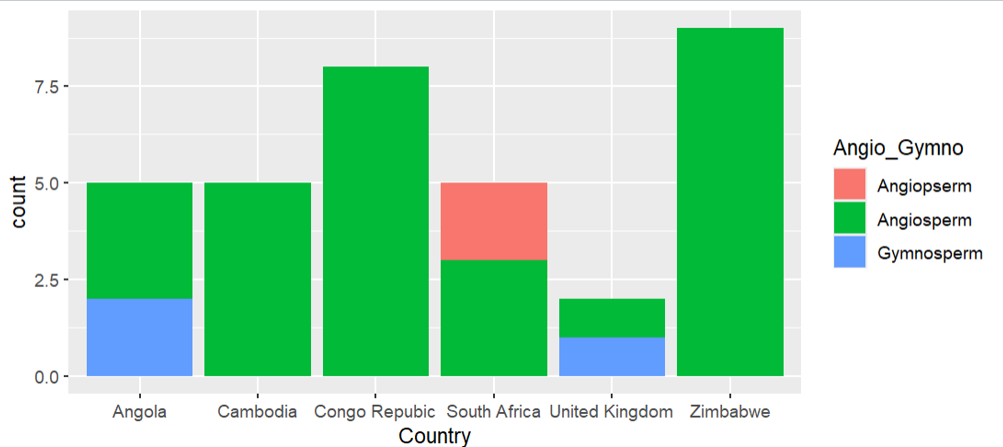
I wanted to see the Angiosperm / Gymnosperm relation by country.
I see that a mispelled word in my dataset caused R to create three categories.
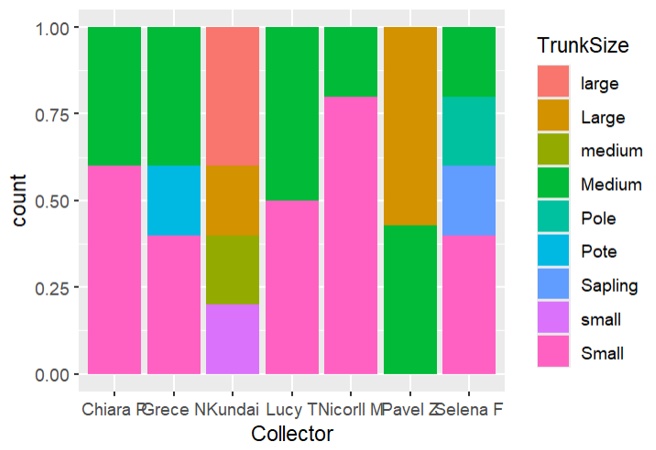
Being unable to fix that error without touching the original dataset and then re-upload it I decided to try with another variable, so to compare the collectors to the trunk size,
using this code
despite the satisfaction of being able to create this very colourful plot, the datas are categorised wrong because of mispelling.
Again, being unable to fix it using R, I tried again and again with more variables within the same dataset until I found one variable that seems all correct (mostly because I don’t know the original size of your leaves!)
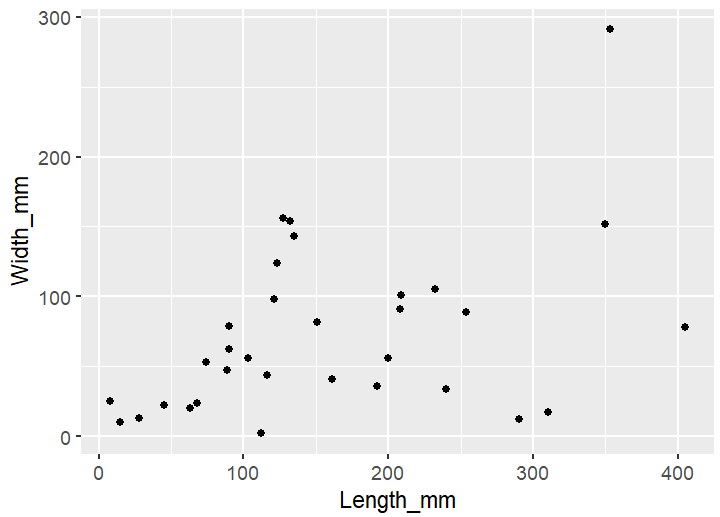
most of the leaves we collected are less than 200 mm long and 100 mm wide
Reflection: data are often recorded directly in the field, often in difficult conditions and with many things that can cause distraction, this exercise made me think at the importance of having a solid data collection methodology designed to reduce human error, and that I need to improve my knowledge to prepare data (I constantly mispell words and do typos!)
Hi Selena , very good point about colorful plot for colorblind people! (my colleague is colorblind and since they told me I try to do all the graphs in the presentations with colors he can see too)
But also many papers are published in black and white only, how can we render line plot like yours in a black and white image?
Great question! I think putting points of differing shapes on the lines would be one way to address the lack of differing colour options on such plots.
 that you’ve created during this module
that you’ve created during this module you used to create it, surrounded by ```
you used to create it, surrounded by ``` the plot; what insight can you gain?
the plot; what insight can you gain? next step, challenge you solved, or problem you still have
next step, challenge you solved, or problem you still have to a coursemate
to a coursemate