Tried to explain all for my own benefit. Detection functions and effective strip width got me a little confused as to how to practicly calculate however…
Detectability is how expected (the probability) it is that we can detect an object if it is there in the transect. It is usually 1 if the object is on the transect and less than one as the distance between the transect and the object increases. It is important this detectability is considered in conducting distance sampling because you are correcting results based on the varying conditions that feature in the areas being sampled.
The four assumptions used in distance sampling are (1) that transects are randomly placed. This means that they cannot follow any established roads or animal trails or purposely cross through areas where it is known animals would frequent. This random placement is to avoid bias with results likely being unrepresentative of the entire area. (2) detection is certain means that if there is an animal on the transect line, they will be detected there. This is important because if objects at the line are missed, the estimate will be biased low. In the survey design, actions must be identified that will ensure that this detection is certain. (3) No movement – animals must be detected and accurately placed (bearing and distance) by the surveyor before it has moved. If measurements are taken after the fact and in response to the surveyor’s presence, then density estimates will be less reliable. (4) Accurate measurements need to be assured using appropriate tools. The bearing and the distance of the animal to the surveyor are used to calculate the final density and thus impact results.
The detection function is a model that describes the chance of detection between 0 and 1 over distance to the transect. It shows a decline in observations, the further from the transect. From this model, it also expects that there are some animals that are detected beyond the detection function line, and some that are missed within the line of detection. There is a point in this model where the number of animals detected beyond the line equals the number that was missed, and this distance is called the effective strip width (ESW). Multiplying the ESW by the transect length then gives you the area surveyed.
For this assignment, I decided to explain Effective Strip Width (ESW) because it was the concept I found the most difficult to understand.
Effective Strip Width is the distance from the transect line where the number of animals you detect beyond that distance equals the number of animals you missed within that distance. It helps account for the animals you didn’t see during the survey, giving a more accurate estimate of animal density.
Here’s how it works:
Detectability decreases with distance: The farther you are from the transect line, the harder it is to see animals. Those close to the line are easy to spot, but as they get farther away, they become more difficult to detect.
Detection function: This is represented by a curve that shows how likely you are to spot an animal depending on how far away it is. Near the line, you have a higher chance of seeing it, but the farther you go, the less likely you are to detect the animal.
Balancing missed and detected animals: The effective strip width is the point where the number of animals you miss beyond the ESW is balanced by the number you detect within it.
How to calculate it: You calculate ESW by fitting a detection curve to your survey data. You estimate the distance at which the number of animals you miss balances with those you see. This becomes your effective strip width.
In short, ESW adjusts your data to account for missed animals, ensuring your animal density estimates are as accurate as possible.
Wow, you covered them all! I hope it was a useful exercise for you
To anyone else following @sharyn , choosing just one of the concepts to explain is sufficient, although you are of course welcome to do more if you find it helpful
the point where the number of animals you detect beyond the ESW is balanced by the number you miss within it
So effective strip width depends on the shape of the detection function:
If detection only declines slowly with distance, for example in grasslands or on open water, you’ll have a large effective strip width (you’re surveying a large area effectively), but
If detection drops off rapidly, for example in dense brush or bamboo/tall grass, you’ll only have a very narrow effective strip width
Various assumptions based on the object of interest (target species) of distance sampling increase the reliability of abundance estimates regardless of whether species is conspicuous or not. These assumptions are important to effectively implement distance sampling and maintain the validity of data. I will attempt to explain random placement methods as it may be more applicable to the urban nature preserve I help manage also for my ecology class.
Random Placement: It is a method of randomly placing the lines or points to increase the validity of density estimates. The target species don’t need to be randomly distributed. However, randomly placed lines or points in regard to relevant distances are important to ensure a representative sample of the object of interest. When using the random placement, you have to assume that
• Detection is certain.
• Objects do not move.
• Accurate Measurements.
Using trails and roads as transect lines/points doesn’t replace the reliable random sampling method.
These may be basic questions, but a few procedural content I am trying to understand better are:
When do you consider all target species to be at zero distance? E.g. when you encounter a bird call overhead during a random bird survey, would high or low height make any difference? Does subjectivity play any role?
What equipment is common in measuring the relevant distance to the target species? Is there any equipment that provides instant distance?
I have used line transect for plant population survey, I am wondering if it is similar to estimate wildlife population density.
Also, I am having trouble locating the relevant discussion board. Is there a way to locate which I am supposed to respond?
The assumption that “detection is certain” means that target species located at or near the transect line will be surely detected (i.e., detection probability = 1). In other words, if a target is directly on the line or close to the observer, it will definitely be detected.
The assumption that detection is certain on the transect line is crucial for ensuring the accuracy and reliability of density estimates, otherwise the numbers will be underestimated.
I would say that we are not working with a 3D model, so we assume that the target species on top/above (at any height) of the transect line would be detected. But I do guess it would make a difference, because imagine you have a dens canopy over your head, and a bird flying above - the canopy will influence its detectability, isn’t it? But not so sure about this one!
For distance, I think range finders are normally used.
Random placement is one of the four assumptions of distance sampling, and you list the other three here too. To clarify, all four of them must hold in order for your analysis to give you density estimates that are reliable and unbiased
If animals do move in response to the observer (such as lagomorphs, small deer or ground-feeding birds flushed out of hiding), but distance and bearing are measured to the original location, the assumption has not been broken
As @Nuria says, laser rangefinders give an instant distance, assuming there is a clear line of sight to the animal. In the absence of such equipment, I recommend a team practises distance estimation together as a pre-survey training exercise, with objects at known distances from the line (or measured immediately) to give feedback and improve estimation ability. There will be differences in people’s ability to estimate distances accurately, but these can be reduced with regular training
In general, it’s harder to estimate larger distances accurately, which is one reason why we remove (truncate) extreme observations before fitting our detection function. We’ll cover this in the Analysis course
@Nuria & @LucyTallents, Thank you for your responses and clarification on distance measurement tools and distance sampling assumptions. I will look forward to learning more in the analysis unit.
This is an equation that gives us the relationship between detection probability and distance - i.e. how likely we are to detect an individual at a defined distance from the transect line or point. The detection function can be represented as g(y), where y is the perpendicular (line transects) or radial distance (point transects). This equation will always between 0 and 1. As we assume that detection is certain at zero distance from the transect, g(0) = 1.
This equation can be plotted as a line of a graph, with probability of detection on the y axis, and distance from transect line on the x axis. Since detectability usually decreases with increasing distance, we usually will see a line that curves down to the right.
When this line is plotted onto the frequency histogram of detections, the area under that line shows the number of individuals detected. The area above this line indicates the proportion of individuals not detected. This allows us to estimate density.
@LucyTallents I have a few questions from the Buckland chapter it would be great if you can clarify - let me know if these should be posted somewhere else!:
1)They mention that an observer can travel at variable speeds on a line transect, but surely this has an effect on likelihood of detection - e.g. that you are likely to detect more individuals the longer you spend, or less likely as more individuals become aware of your presence and move away. Do transect speed and total time for the survey need to be controlled/standardised/accounted for in some way?
2) They also mention the observer can move off the transect line, as long as the total distance used for calculations is still the transect length. But doesn’t this also introduce a variable that needs to be controlled? And it would also change distance calculations if looking at the angle between observer and object - so would you also have to calculate distance of the observer from the line?
3) Since the areas surveyed through transects are samples, do we have to assume a closed population within the total survey area? Since we are usually looking at wild populations rather than captive, it seems difficult to define a specific wider study area that we are sampling from? Should it always have clear boundaries that would make it likely to be a closed population (e.g. roads, fences, rivers, habitat boundaries)? Or does open vs closed not affect this method?
4) If I’ve understood right, we assume populations are distributed in the study area according to stochastic processes, but since this is unlikely in reality, we then measure and treat as covariates things that may affect distribution, such as habitat type and prey availability. Since there are lots of things that might affect distribution, how do you decide what to measure and can we ever be confident we’ve measured the things that will most likely affect distribution?
5) Since we assume that an animal hasn’t moved at the point of detection, would that mean an animal clearly retreating from the observer would just not be counted? Or counted but with a note that it was moving away, and does that affect how you analyse the data?
Accurate measurements are one of the four assumptions of distance sampling that create trustworthy results.
Measurements needed:
1) The distance between the observer and the animal/sign at first detection (radial distance)
2) The angle, or bearing, between the observer and the animal/sign where the transect line = 0.
The perpendicular distance can now be calculated (radial distance X sin(angle))
Why the measurements are needed:
The perpendicular distances for all sightings will be collated to create a frequency histogram and calculate your detection function.
The influence of observer bias on distances and angles can be limited by training field staff on tried and tested tools used to estimate distance and record angles.
Thanks Sausilwal, I found the questions you asked really useful for my own learning. Thank you Nuria and Lucy for your answers. I hadn’t thought of using rangefinders before (had to Google them!) and thought that training on distance estimation was the only option.
One of the four key assumptions of distance sampling is ‘no movement’. This refers to the idea that the animals being surveyed shouldn’t move in response to the person carrying out the survey (the observer) before their distance is recorded. Measures of population density will be skewed if the distance from the observer to the animal is not accurately recorded.
For example, if the animal acts out of curiosity and moves towards the observer before it is recorded, then it would appear in the data as if they were closer, leading to an overestimation of detectability and a potentially an overestimated population density. Conversely, if an animal is disturbed by the observer and moves away (like a deer when startled), they will be recorded at a greater distance from the observer which will also affect the accuracy of the detection function and potentially lead to an underestimate of population density. The animals may also not be recorded at all, if they move away before being detected by the observer due to noise or smell.
Researchers can attempt to mitigate this issue by minimising noise and using camouflage when conducting surveys. They could also use camera traps and acoustic monitoring (remote detection) in order to eliminate the human presence and the risk of disturbing animals. Tools such as binoculors or thermal imaging could also help to detect animals before they become aware of and react to a human presence.
My question for @LucyTallents or the group would be how can researchers account for potential movements in their findings? I feel like some degree of movement from first sighting to recording is probably inevitable, so can this be factored in?
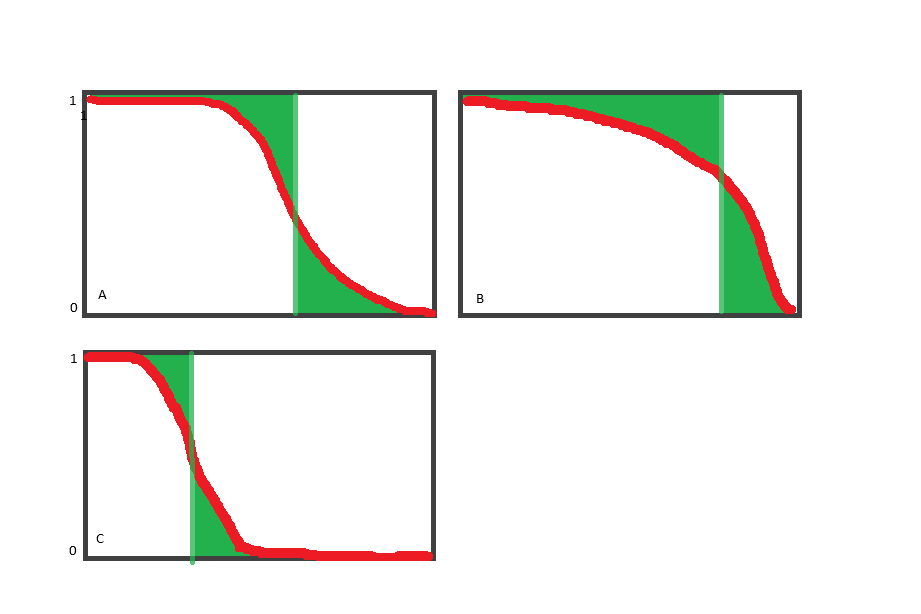
As all the concepts already had definitions given for them, I thought I’d try to show Lucy’s reply to Morena on different shaped detection functions in a diagram. Please forgive the Microsoft paint.
Figure A: detection declines in proportion (approx.) to distance from the transect, so we have medium sized ESW.
Figure B: detection declines slowly with distance; this could occur in a habitat with long lines of site and little vegetation such as grassland. ESW is large.
Figure C: detection drops sharply, for example in a habitat with dense vegetation like a rainforest with a thick understory. ESW is narrow.
@LucyTallents Please can you explain how different detection functions and ESWs affect our analysis?
If the ESW was narrow, would we need to have more transects to increase the sample size for example?
Does a large ESW mean we can give our estimates with more certainty?
During field surveys you should measure the distance to where the animal was before being startled (if known!), rather than its location when seen. This is easier if it was hiding in a lone clump of bushes, but virtually impossible if you’re working in forest where it could have been anywhere in the understorey ahead/alongside you
It is possible to diagnose and account for movement away from the transect during the analysis stage, provided the avoidance movements aren’t too great